
Image Generation
mage generation is the process of using computer algorithms to create digital images from scratch or modify existing ones. There are several methods for image generation, including using generative models, such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and autoregressive models.
Generative models use deep learning algorithms to learn the underlying distribution of a set of images, allowing them to generate new images that are similar in style or content to the original images. GANs, for example, use two neural networks, a generator and a discriminator, to create new images that can fool the discriminator into thinking they are real.

VAEs use a similar approach to GANs, but instead of a generator and discriminator, they use an encoder and decoder. The encoder compresses an image into a lower-dimensional space, while the decoder reconstructs the image from the compressed representation.




Autoregressive models generate images one pixel at a time, using the previous pixels as context. These models are slower than GANs and VAEs but can generate high-quality images with fine details.
Image generation has many practical applications, including creating synthetic training data for machine learning models, generating realistic-looking images for video games and movies, and generating images for data visualization and art.
Semantic Image-to-Photo Translation
Semantic image-to-photo translation is a computer vision task that involves generating a realistic photo from a given semantic or high-level description of the image. The goal is to translate a semantic representation of an image into a photo that accurately reflects the intended visual content.
This task is challenging because it requires the model to have a deep understanding of the semantic content of the image, such as object categories, their spatial arrangements, and attributes such as colors and textures. It also requires the model to generate visually appealing and realistic photos that match the semantic description.

Recent advances in deep learning and generative models, such as Generative Adversarial Networks (GANs), have enabled significant progress in semantic image-to-photo translation. These models are trained on large datasets of paired semantic representations and photos and learn to generate photos that match the given semantics.
Semantic image-to-photo translation has many potential applications, such as in the creation of photorealistic images from textual descriptions, or in the design of virtual environments and augmented reality applications.
Image Resolution Increase
Increasing the resolution of an image means adding more pixels to the image to make it appear sharper and clearer. However, increasing the resolution of an image is not always a straightforward task and may result in a loss of image quality or blurriness if not done correctly.
There are various techniques that can be used to increase the resolution of an image, such as:

- Interpolation: This involves adding more pixels to an image by analyzing the existing pixels and predicting what additional pixels might look like based on surrounding pixel values. However, this technique can often result in a loss of detail and clarity in the image.
- Superresolution: This technique involves using machine learning algorithms to analyze low-resolution images and generate high-resolution versions of them by filling in the missing details.
- Resampling: This technique involves changing the size of the image without altering its aspect ratio by either adding or removing pixels from the image. This technique can result in a loss of detail and clarity in the image.
It’s worth noting that while it is possible to increase the resolution of an image using various techniques, it’s impossible to create information that wasn’t originally present in the image. So, the best way to obtain a high-resolution image is to capture it at the highest possible resolution from the beginning.
3D Shape Generation
3D shape generation refers to the process of creating three-dimensional shapes or models using computer software. This can involve creating shapes from scratch or modifying existing shapes to create new ones.
There are various techniques and tools that can be used for 3D shape generation, including parametric modeling, sculpting, and procedural modeling. Parametric modeling involves using mathematical equations and parameters to create and modify shapes. Sculpting involves manipulating a virtual clay-like substance to create shapes.
Procedural modeling involves defining rules and parameters for the generation of shapes, which can then be automatically generated by the computer.

Some popular software programs used for 3D shape generation include Blender, SketchUp, Maya, and 3ds Max. These programs offer a wide range of tools and features for creating and modifying 3D shapes, including the ability to add textures and lighting effects, animate shapes, and render final images.
3D shape generation has numerous applications in industries such as architecture, engineering, product design, and entertainment. It is also used in research fields such as medicine, where 3D models of organs and tissues can be generated for analysis and diagnosis.
Text-to-Speech Generator
Hello! I can certainly help you with generating text-to-speech.
There are many tools available for generating text-to-speech, including free and paid options. Here are a few options to consider:
- Google Text-to-Speech: This is a free option that works with Google Assistant, Google Translate, and other Google applications. It’s available on both Android and iOS devices.
- Amazon Polly: This is a cloud-based service that allows you to convert text into lifelike speech. It offers a range of voices and languages, and you can use it for free up to a certain number of characters per month.
- Microsoft Azure Text-to-Speech: This is another cloud-based service that offers natural-sounding voices in several languages. You can use it for free up to a certain number of characters per month.
- NaturalReader: This is a desktop application that converts text to speech. It offers several voices and allows you to adjust the speed and volume of the speech.
- Voicely: This is a text-to-speech software that allows you to convert any written text into speech. It offers more than 60 voices, and you can customize the pitch, speed, and volume of the speech.
I hope this helps you find the right text-to-speech generator for your needs!
Speech-to-Speech Conversion
Speech-to-speech conversion refers to the process of automatically converting spoken language from one language to another. It involves the use of advanced artificial intelligence and natural language processing algorithms to recognize and interpret speech, and then generate output speech in the target language.
There are several approaches to speech-to-speech conversion, including rule-based, statistical, and neural machine translation. In a rule-based system, a set of linguistic rules is defined to translate the source language into the target language.
Statistical machine translation systems use statistical models to learn the patterns and relationships between words and phrases in different languages to generate translations. Neural machine translation systems use deep learning techniques to learn the translation patterns directly from large amounts of data.
Speech-to-speech conversion technology is particularly useful for applications such as language translation, language learning, and communication with people who speak different languages. It can also be used to assist people with hearing or speech impairments by converting spoken language into written text or sign language.
Text Generation
Sure, I can help with text generation! Text generation refers to the process of using a computer program or algorithm to generate new pieces of text that are similar in style or content to existing text. There are several different approaches to text generation, including rule-based systems, statistical language models, and neural networks.
One popular approach to text generation is to use a neural network architecture called a recurrent neural network (RNN). RNNs are designed to work with sequential data, such as text, and they can learn to generate new text by predicting the most likely next word or character given a sequence of previous words or characters.
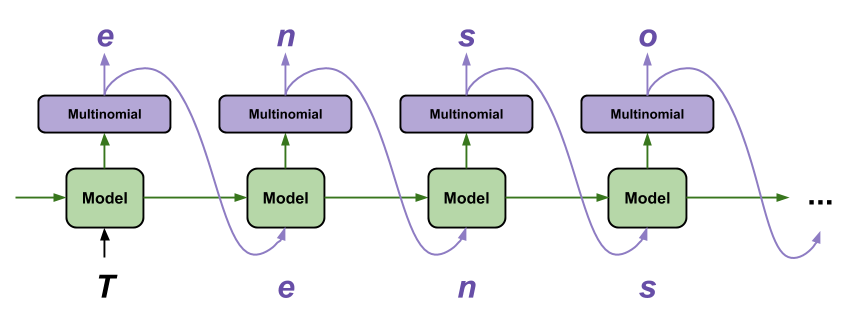
Another approach to text generation is to use a language model, which is a statistical model that is trained on a large corpus of text to predict the likelihood of a particular sequence of words or characters. Language models can be used to generate new text by sampling from the model’s probability distribution to select the most likely next word or character.
There are also several text generation tools and platforms available that use these techniques to generate text, such as GPT-3, which is a language model developed by OpenAI that can generate highly realistic and coherent text. Other popular text generation platforms include Hugging Face, AI Dungeon, and Talk to Transformer.
If you have any specific questions or topics that you would like me to generate text on, feel free to let me know!
Code Generation
Code generation refers to the process of automatically generating source code or executable code from a high-level specification or model. The purpose of code generation is to increase productivity, reduce development costs, and improve code quality by automating repetitive and error-prone tasks.
Code generation is used in a variety of software engineering activities, such as software development, testing, and maintenance. It can be applied to a wide range of programming languages and platforms, including web development, mobile development, and desktop development.

Code generation can be performed using different techniques, such as templates, code snippets, macros, and code generators. Templates and code snippets are simple tools that allow developers to reuse code fragments and avoid repetitive coding tasks.
Macros are more advanced tools that allow developers to automate complex coding tasks by defining a set of rules or instructions. Code generators are the most powerful tools for code generation, as they can automatically generate code based on a set of specifications or models.
There are many benefits of using code generation, including increased productivity, reduced development costs, improved code quality, and faster time-to-market. However, code generation also has some drawbacks, such as reduced control over the generated code, decreased flexibility, and increased complexity.
Therefore, it is important to carefully evaluate the use of code generation in a specific development project and choose the most appropriate technique for the task at hand.
Music Generation
Music generation is the process of creating new music using computer algorithms, machine learning, and other technologies. There are various techniques for generating music, such as rule-based systems, statistical models, and neural networks.
Rule-based systems involve specifying a set of rules that govern the creation of music, such as harmony, rhythm, and melody. These rules can be programmed into a computer algorithm, which then generates new music based on the given rules.

Statistical models involve analyzing a large dataset of existing music and using statistical techniques to identify patterns and structures within the music. The model can then use this information to generate new music that is similar in style and structure to the original dataset.
Neural networks are a type of machine learning algorithm that can learn to generate music by analyzing a large dataset of existing music. The neural network is trained on this dataset and can then generate new music that is similar in style to the original music.
Music generation has many applications, such as in the creation of background music for videos, video games, and other media, as well as in the development of new musical styles and genres. However, it is important to note that music generated by machines still lacks the emotional depth and creativity of music created by human musicians.
Image-to-Image Conversion
Image-to-image conversion refers to the process of transforming an input image into an output image with a different visual appearance, while preserving the underlying content or structure of the input image. This process can involve various tasks, such as image colorization, image super-resolution, image style transfer, and image inpainting, among others.
Image-to-image conversion is a key research area in computer vision and has numerous applications in areas such as graphics, video processing, and robotics. It involves the use of deep learning techniques such as convolutional neural networks (CNNs) and generative adversarial networks (GANs) to learn complex mappings between input and output images. These models are trained on large datasets of paired input and output images to learn the underlying patterns and relationships between them.
One popular approach to image-to-image conversion is conditional GANs, which can generate high-quality, realistic-looking images that closely match the desired output style. Another approach is to use encoder-decoder architectures, which can learn to map low-resolution input images to high-resolution output images, as is the case in image super-resolution.
Overall, image-to-image conversion is a challenging but exciting area of research that has the potential to transform the way we process and manipulate visual content.



